What is Library Characterization? feat: SPICE, and Static Timing Analysis (STA)


Overview of SPICE and STA
In modern high-density VLSI design, it's crucial to ensure that an integrated circuit (IC) operates correctly and reliably at its specified clock period.
This is achieved through rigorous timing analysis, which identifies potential performance bottlenecks and ensures compliance with timing constraints.
Static Timing Analysis (STA) is the industry-standard methodology for verifying the timing performance of digital designs. It's essential for optimizing Power, Performance, and Area (PPA), which represents a key challenge for designers and architects.
Have you ever used SPICE simulation?
It's known for being highly accurate, but also very slow. Those who have worked on design from RTL to GDS often hear that tools like PrimeTime are the "golden standard" or "golden reference."
While place and route (P&R) and synthesis tools use relatively lightweight timing analysis, PrimeTime performs extremely precise calculations, though it is slower.
PrimeTime, in turn, considers SPICE as its golden reference. Promotional materials from Synopsys confirm that PrimeTime aims for the same level of accuracy as PrimeSim HSPICE.
The Role of Library Characterization
The input timing files for an STA tool are called libraries. These libraries are created by characterization tools such as PrimeLib (Synopsys) or Liberate (Cadence).
The values written into these libraries are calculated by SPICE tools like PrimeSim, HSPICE, FineSim (all from Synopsys), and Spectre (Cadence).
Since SPICE simulations are very slow, it's impractical to run them for every cell in a complex VLSI circuit. Therefore, the calculated values for each standard cell are pre-calculated and stored in a database file. This way, when an EDA tool needs to perform a timing calculation, it can simply look up the values in the database, which is much faster. This is the purpose of library characterization.
Evolution of Cell Delay Models
Early delay models used a single, fixed constant for cell delay, which later evolved into linear functions. However, the intrinsic behavior of CMOS gates is inherently nonlinear. A logic gate's input slew and output transition are not static; they depend heavily on the characteristics of the input signal and the electrical load connected to the gate's output.
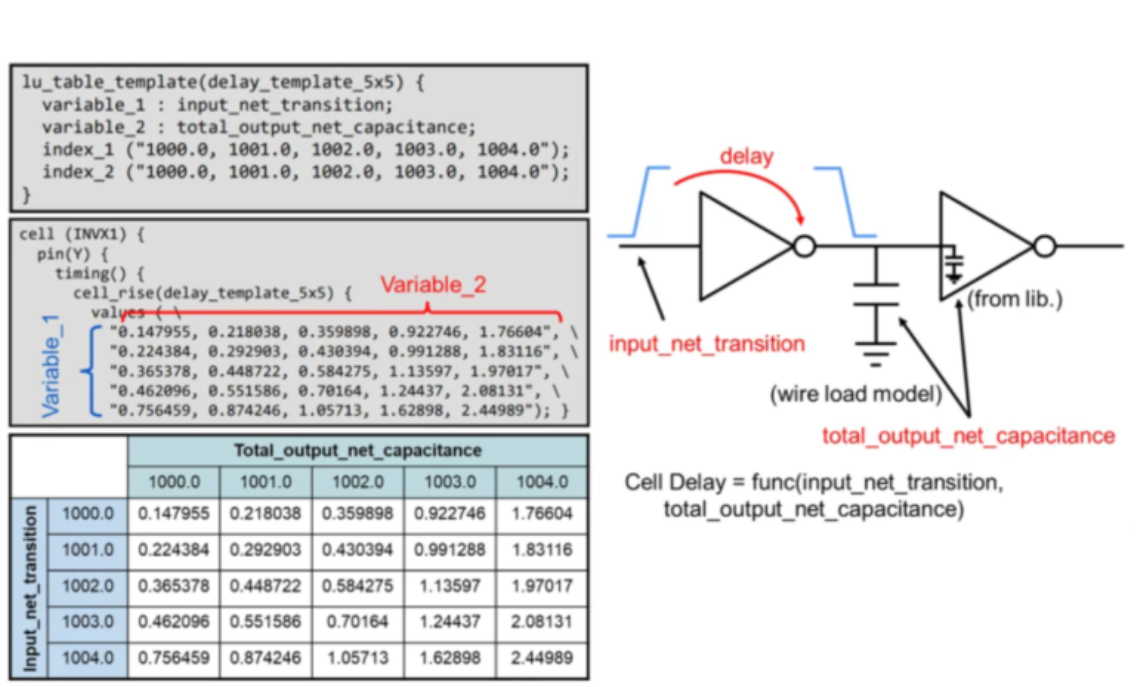
This dynamic, nonlinear dependency requires sophisticated models that can accurately capture these variations. The Non-Linear Delay Model (NLDM) was specifically developed to address this nonlinear behavior, providing a more accurate representation of timing characteristics than linear models.
The Non-Linear Delay Model (NLDM)
While various physical factors can affect cell delay, the NLDM table, which is primarily based on input transition and output capacitance, is widely adopted. It's a voltage-based delay calculation model that is essential for characterizing a cell's response in a library.
The nonlinear nature of CMOS transistor switching—including variable effective resistance and dynamic Miller effects—directly causes cell delay and output slew to depend nonlinearly on input transition time and output load. Without models like NLDM, simple linear approximations would lead to significant inaccuracies in timing predictions, potentially compromising chip functionality and performance.
Key Concepts:
- Input Transition (Input Slew): Quantifies the time a signal takes to reach between two defined voltage thresholds (e.g., 10% to 90% or 20% to 80% of Vdd).
- Output Capacitance (Output Load): Represents the total effective capacitance presented at the cell's output pin.
NLDM Lookup Table (LUT)
The NLDM approach relies on a 2D lookup table (LUT) to represent a standard cell's complex, nonlinear timing characteristics. This table-based method efficiently captures cell timing dependencies without complex analytical equations.

The table is indexed by the two main independent variables: input transition time and output capacitance. For each specific combination of these values defined by the grid points, the table stores the pre-characterized corresponding values.
A denser grid (more points) provides higher accuracy by reducing interpolation errors but significantly increases the computational resources and time needed for SPICE characterization. This also results in a much larger library file, which can slow down subsequent STA runs. Conversely, a sparser grid is faster and smaller but less accurate. Therefore, the strategic selection of these discrete points (often called breakpoints) is a crucial step in the library characterization process. This choice directly impacts the "Quality of Results (QoR)" that can be achieved in the design flow.
What is PT-SPICE (STA-SPICE) Accuracy?
Most EDA tools consider PrimeTime (Static Timing Analysis) timing as the golden reference timing, and the final signoff is performed using PrimeTime just before chip tape-out. STA tools simply use values modeled by lookup tables.
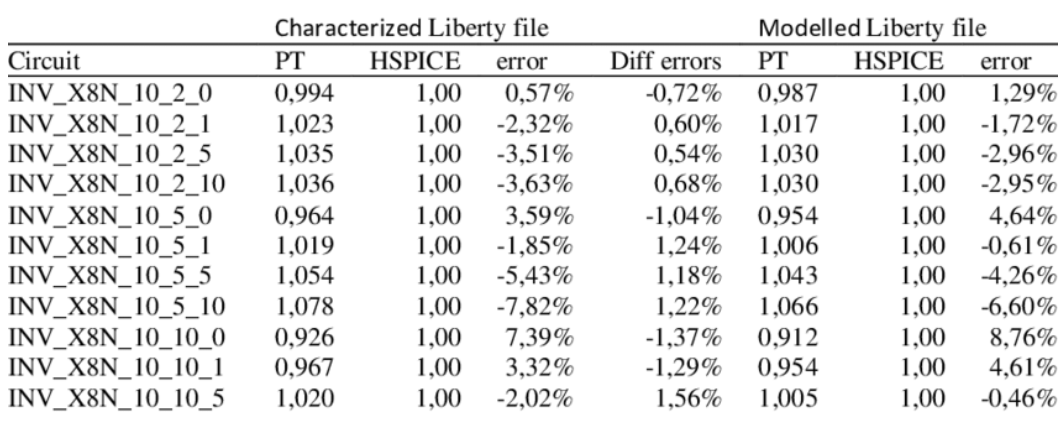
Since LUTs are created using SPICE, SPICE is a more golden value than STA. Ultimately, STA tools must perform accuracy evaluations with SPICE tools.
Then What is DB?
The NLDM lookup tables are stored in Liberty (.lib) files, which are the industry-standard format for representing timing, power, and functional information for standard cell libraries.
A compressed version of this file is the .db file, which is created by tools like Synopsys's Library Compiler. These files are essential inputs for various Electronic Design Automation (EDA) tools, including logic synthesis, physical placement, and STA.
What is DRC in Library?
Tools often prioritize fixing Max transition violation and Max capacitance violation first.
This is because if a cell's transition or capacitance values fall outside the table's range, the tool must resort to extrapolation. In statistics, extrapolation is known to produce poor accuracy. In this context, it leads to significant inaccuracies in the timing calculations compared to SPICE.
Library characterization engineers verify the accuracy against SPICE within the interpolation range.
The points where maximum capacitance or transition violations occur are unverified and therefore lead to inaccurate timing. This is why EDA tools attempt to fix these violations first: they prioritize eliminating the areas of calculation uncertainty over the "sure" violation points.

![[STA] Synchronous Clocks vs. Asynchronous Clocks](https://images.unsplash.com/photo-1533749047139-189de3cf06d3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fGNsb2NrfGVufDB8fHx8MTc1NTQzMzg1OHww&ixlib=rb-4.1.0&q=80&w=600)

